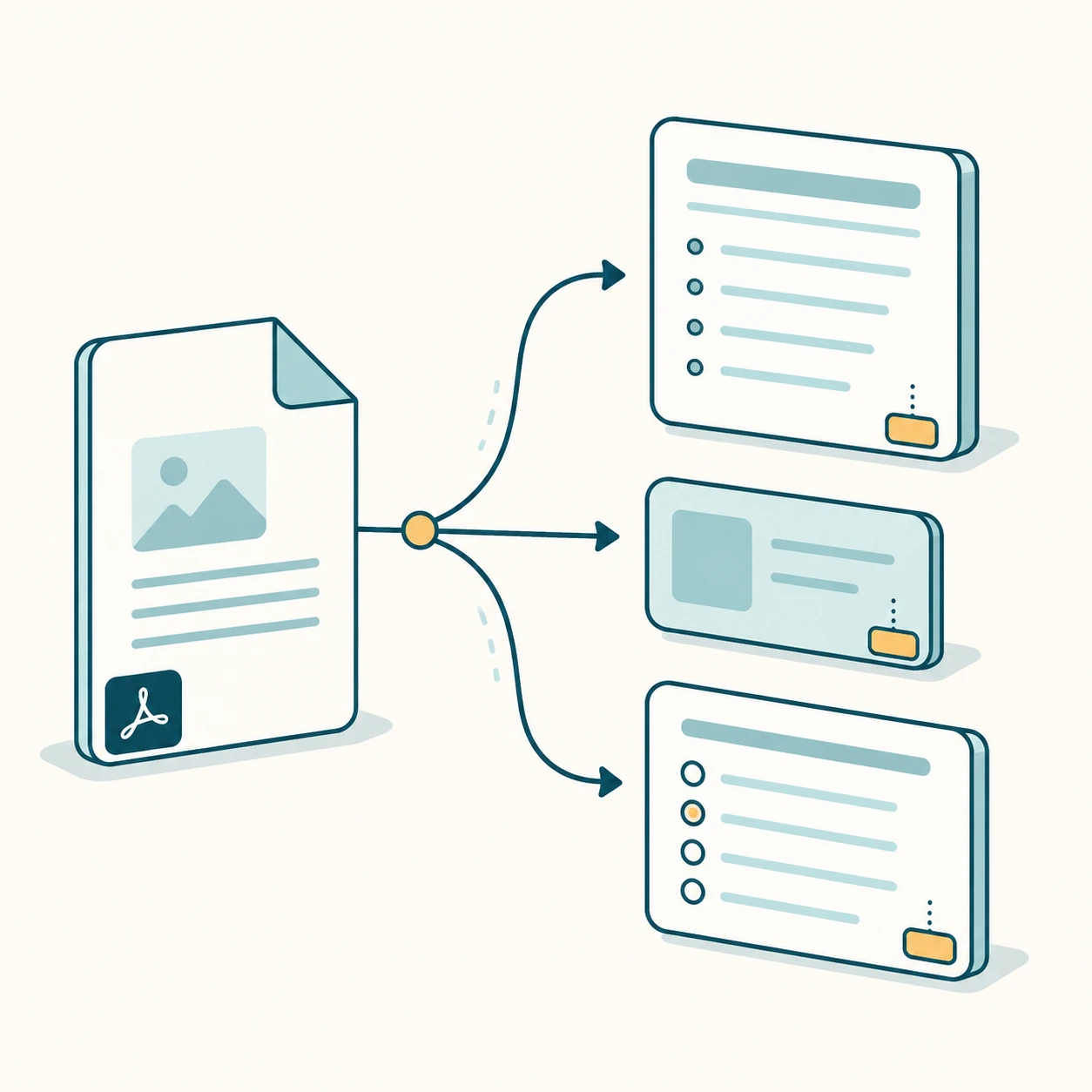
PDF 转笔记
把源材料变成可复习输出,而不是泛泛的 AI 填充内容。
PDF 转笔记的搜索意图不只是要一段摘要。学生真正需要的是可复习、可验证、可继续练习的学习材料。这个页面聚焦把 PDF 转成学习笔记,同时保留页码引用,让用户能从阅读直接进入复习和自测流程。如果没有结构、页码和后续题目,生成结果很难真正提高学习效率。
适合处理哪些文档
这个流程最适合课件、教材章节、讲义、公开报告和带可选中文本的论文。扫描件需要 OCR,成本更高、失败模式更多,因此应该作为付费或后续能力。MVP 先把文本型 PDF 做稳定,用户才能信任生成出来的学习笔记。
学习笔记结构
生成结果不会只堆成一段长文字,而是拆成标题、要点、摘要和关键知识点。页面还会附带闪卡和测验题,让用户从理解进入主动回忆。这样的输出比普通总结更完整,也更适合复习场景。
引用和可信度
页码引用是这个工具的信任边界。界面会在笔记、闪卡和题目旁显示来源页 chip,用户可以回到原始 PDF 查看上下文。如果模型没有依据,输出应该保持克制,而不是编造看似合理的知识点。
输出质量如何判断
好的学习笔记应该让用户少做整理工作,而不是增加新的负担。首版会重点检查标题是否清晰、要点是否能回到来源页、闪卡是否适合背诵、题目是否能检测理解。只要用户能在几分钟内从阅读材料进入复习动作,这个页面的核心价值就成立。页面文案也要把限制讲清楚:免费预览适合短资料,复杂扫描件和长文档需要更高成本的解析流程,导出和云端历史则属于可复用资产。
用户边界和失败提示
真实用户会上传空白文件、图片扫描件、受保护资料、超大课本,也会只粘贴几句话来试功能。页面需要在这些边界上给出清楚反馈:内容太短就要求补充材料,文件太大就提示免费限制,扫描件无法读取就解释需要 OCR。相比通用报错,这种提示更能保住用户信任,也能减少无效模型调用。对产品转化来说,清楚的失败说明比沉默等待更重要,也能让用户知道下一步应该换文件、缩短内容还是直接使用粘贴入口。
相关学习工具
每个页面都对应一个关键词组,并链接到相邻工作流,帮助搜索引擎理解 PDF 到学习输出的主题集群。
常见问题
PDF 转笔记需要登录吗?
短文本型 PDF 可以免登录预览。导出、云端历史、长文档和 OCR 需要账号或付费方案。
会保留 PDF 原始排版吗?
不会。MVP 先提取文本和页码,不复刻 PDF 的视觉排版。
从上方真实生成器开始。
免费预览保持限制,但生成的笔记、闪卡、测验题、答案解析和来源页码,与付费工作流使用同一套结构化输出形态。
查看付费导出选项